
티스토리 뷰
먼저 저는 헬스 동행을 구하는 어플리케이션인 'HELPARTY'를 개발 중에 있습니다. 나중에 이 어플리케이션 서버의 처리량이 한계에 도달했을 때 서버를 확장하는 방법에 대해 알아보았습니다. 먼저 서버의 성능을 올리는 방법에는 2가지가 있다는 것을 알았습니다.
Scale Out vs Scale Up
첫번째로 Scale Out과 Scale In이 있습니다. 이것에 대한 정보는 이 포스팅을 참조해주시길 바랍니다.
스케일 아웃 (Scale Out) vs 스케일 업 (Scale Up)
#1 스케일 아웃 정의 접속된 서버의 대수를 늘려 처리 능력을 향상시키는 것이다. 서버가 증설됨에 따라 트래픽을 나누어 갖게 되고, 각각의 서버가 이를 처리하게 된다. 수평 스케일로 불린다.
hamryt.tistory.com
이렇게 조사를 마치고 저는 이제 스케일 아웃을 사용하기로 정했지만 데이터 정합성 문제를 해결해야 하는 문제가 남았습니다.
왜 이 정합성이 그렇게 중요한지 알아보자

로그인 상황을 생각해보겠습니다, 사용자들이 로그인을 하면 각 서버에서 해당 사용자에게 로그인 했다는 인증을 넘겨줍니다. 아예 로그인에 대한 정보를 클라이언트에게 넘겨주면 네트워크를 통해 탈취 당할 위험이 있고, 또 클라이언트가 받았을 경우에도 쿠키에 저장하게 될 텐데 쿠키는 오픈되어 있기 때문에 보안에 취약하기 때문이죠. 그렇기 때문에 다른 곳에 로그인 정보를 저장해야 합니다. 따라서 서버에 저장해서 오픈되지 않는 세션에 로그인 정보를 저장하고 클라이언트에게는 JSESSIONID라는 로그인을 했다는 인증 정보를 넘겨줍니다.

문제는 이 세션들은 다른 서버에게 공유가 되지 않는다는 점이 Scale Out에서 문제가 됩니다. 서버를 여러대 더 사서 Scale Out했다고 가정해보겠습니다, 그리고 저는 하나의 서버에 배정돼서 로그인을 하고 웹서비스를 사용합니다. 이때 제가 사용한 서버에는 제것의 세션 정보가 있겠지만 다른 서버 노드들은 제것의 세션 정보를 모르기 때문에 제가 로그인 인증이 돼야 사용할 수 있는 서비스를 사용하려 하면 제것의 세션을 저장하고 있는 서버에서만 요청을 보내야 합니다.

내 자신 말고도 다른 사람들도 로그인을 하고 서비스를 사용한다고 할 때 만약 이 사람들이 모두 제가 사용한 서버에서 세션을 저장한 사람들이라면 서버 대수가 아무리 많아도 이사람과 제가 서비스를 사용할 때는 하나의 서버만 사용하게 됩니다. 유연성이 매우 안좋아지는겁니다. 이렇게 되면 Scale Out한 이유가 없어집니다. 그리고 이 서버가 만약 장애가 발생했다고 하면 저는 다시 다른 서버에 재로그인해서 다른 서버에 세션을 저장해야합니다. 즉 가용성이 떨어집니다.
이처럼 데이터 정합성은 서버를 여러대 사용하는 Scale Out 방식에서 매우 중요합니다. 그래서 이를 해결하기 위한 방법을 다시 알아보겠습니다.
Session 불일치 해결 방식
세션 불일치 문제를 해결하는 방법으로는 크게 3가지가 있습니다. 첫번째로, Sticky Session 방식이 있고 두번째로, Session Clustering이 있습니다. 마지막으로, Session Storage 분리 방식이 있습니다. 이에 대한 조사도 다른 페이지에 적어놨습니다. 아래의 포스팅을 참조해주시기 바랍니다.
Sticky Session, Session Clustering, Session Storage 분리
Sticky Session 고정된 세션을 말한다. 클라이언트는 자신의 세션이 저장된 서버에서만 응답을 받게 된다. 로드벨런서는 클라이언트의 요청을 받으면 쿠키에 지정된 서버 정보를 확인하고 그 서버
hamryt.tistory.com
조사 결과 Session Storage 분리 방식이 최선이라는 것을 알게되었습니다. 그럼 이제 Session Storage를 분리하는 방법을 생각해보겠습니다.
Storage의 종류
먼저 Storage의 종류에는 두가지가 있습니다. 먼저 첫번째로 Disk방식으로 되었는 데이터베이스가 있고 두번째로 In-Memory 기반의 데이터베이스가 있습니다.
Disk Database
먼저 디스크는 MySql, Oracle에서 사용하는 방식입니다. 이것의 특징은 데이터를 디스크에 저장한다는 것입니다. 진짜 디스크를 돌리면서 거기에 저장합니다. 진짜 디스크에 저장하기 때문에 전원이 공급이 안되도 정보를 적어놓은 디스크에는 정보를 잃지 않고 잘 유지하고 있습니다. 하지만 큰 단점이 하나 있는데 속도가 너무 느립니다.
In-Memory
In-Memory는 데이터를 메모리에 저장합니다. 그래서 I/O속도가 디스크와 비교해서 매우 빠릅니다. 하지만 이것또한 단점이 있는데 전원이 공급되지 않으면 기억하고 있는 데이터를 모두 잃어버리게 된다는 것입니다.
그럼 저는 무엇을 사용해야할까요..
지금 제가 Scale Out을 하고 그 과정에서 해결하려는 것은 세션 불일치 문제입니다. 생각해보면 Session은 영구적인 저장이 필요하지 않습니다. 로그인을 해도 창을 닫으면 로그아웃이 자동으로 되야합니다. 그래야 사용자의 정보가 보호됩니다. 그리고 로그인을 하고 있더라도 로그인을 다시하는 수고보다 개인정보가 더 중요한 요즘은 지정한 시간을 넘기면 자동으로 로그아웃됩니다. 그렇기 때문에 세션 정보는 영구적인 정보 저장을 약속한다는 디스크 방식의 데이터베이스는 매력적이지 못합니다. 데이터를 영구적으로 저장하지 못하지만 대신에 디스크에 비해 압도적을 입출력 속도가 빠른 In-Memory 방식이 더 나아보입니다.
그럼 다시 In-Memory방식을 사용한다고 생각했을 때 어떤 데이터 베이스를 사용해야할까를 생각해보겠습니다.
먼저 다른 사람들이 만드는 것을 보니 Redis와 memcached 이 두개의 데이터 베이스를 사용한다는 것을 알게 됬습니다.
Redis vs Memcached
이제 redis와 memcached 둘 중 어느 데이터베이스를 사용할지를 정하기 위해 비교해보겠습니다.
비교
1. 데이터 복원 관점
redis
먼저, redis는 지금 가진 메모리를 스냅샷으로 남겨서 Slave DB에 전체를 저장합니다. 만약 Master DB에서 문제가 생긴다면 Slave DB를 Master로 승격 시켜서 사용하여 서비스를 문제 없이 제공할 수 있습니다. 그리고 RDB와 업데이트를 지속적으로 적용해주는 AOF가 기능이 있습니다. 또한 데이터 파일이 편집 가능한 메모장 처럼 되어있어서 잘못된 명령어로 데이터를 날렸다고 하더라도 .aof 파일에 들어가서 해당 명령어만 지워주면 원래대로 복구 가능합니다.
memcached
memcached는 redis처럼 장애극복기능이 없습니다. 대신에 서버에 데이터를 Hashing알고리즘으로 여러대의 Memcached서버에 데이터를 분산 저장하여 하나의 서버가 다운되더라도 피해가 최대한 적게 하는 방식으로 운영됩니다. 그리고 redis처럼 자체적으로 장애극복기능을 제공하지는 않지만 각 노드에 백업노드를 사용자가 직접 만들어서 장애극복기능을 만들 수 는 있습니다.
2. 응답속도의 균일성 관점
redis
먼저 redis는 대규모 트래픽으로 많은 데이터가 업데이트 될 경우 속도가 일정하지 않게 됩니다. 이것은 jemalloc 알고리즘을 사용하여 매번 malloc과 free를 통해서 메모리를 할당하기 때문이라고 합니다. 그 결과로 메모리 단편화 문제를 만들고 이 때문에 응답속도가 느려진다고 합니다.
memcached
memcached는 이부분에서 장점을 보입니다. redis보다 응답속도 면에서는 일정한 속도를 유지하며 안정적인 모습을 보여줍니다. memcached는 메모리 할당에 있어서 slab allocator를 사용하는데 이것은 내부적으로 메모리 할당을 하지 않고 관리하는 형태로 운영되기 때문이라고 합니다.
3. 싱글 스레드와 멀티 스레드 관점
redis
redis는 싱글 스레드이고 memcached는 멀티 스레드입니다. redis가 싱글스레드인 만큼 병목 현상을 걱정할 수도 있겠지만 Redis 공식 홈페이지에서 보면 redis에서는 데이터가 메모리에서 저장되고, 관리되기 때문에 CPU가 redis에서 병목 현상을 발생시키는 빈도가 적다고 합니다. 그럼에도 CPU의 사용률을 높이고 싶다면 Replication과 Sharding으로 redis의 인스턴스를 더 만들고 각 인스턴스로 데이터를 분산시켜서 사용하면 됩니다.
memcached
memcached의 경우에는 멀티스레드를 사용하기 때문에 redis보다 더 좋은 성능을 낼 수 있는 것이 아닌가 생각해볼 수 있지만, memcached는 명령어를 파싱 하는 것까지만 멀티스레드 형태로 수행되고 실제 데이터에 접근하는 연산들은 Global cache lock으로 인하여 서버 전체의 캐시에 대해 잠금 상태가 되기 때문에 데이터 연산에서는 싱글 스레드처럼 동기화되어 동작합니다. 따라서 redis와 CPU 사용율 측면에서는 다를게 없어 보입니다.
4. Performance
Redis의 버전은 3.07이고 Memcached의 버전은 1.4.14입니다.


Write 성능을 비교했을 때에는 Memcached가 Redis보다 더 뛰어남을 알 수 있습니다.

Read 성능을 비교했을 때에는 Redis가 Memcached보다 더 뛰어납니다.
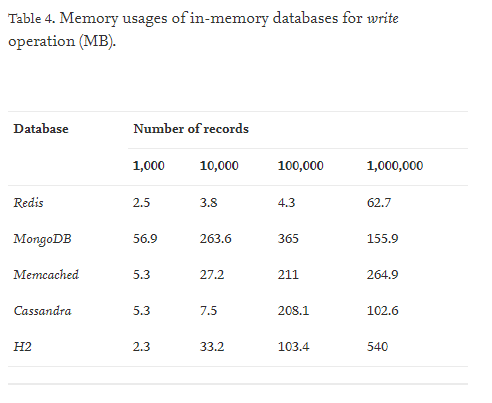

Redis가 Write하는 속도는 Memcached에 비해 느리지만 각 Read와 Write연산을 수행할 때의 메모리 사용량을 보면 Memcached에 비해 효율적임을 알 수 있습니다.
결론
지금까지의 Memcached와 Redis를 비교해봤을 때, 각 데이터는 각자의 장단점을 지니고 있지만 제가 사용하려는 데이터 세션의 측면에서 봤을 때, 로그인 정보를 관리하는 것이 중요하기 때문에 데이터의 읽기/쓰기의 성능이 중요해보입니다. 그리고 자체적으로 Replication기능을 제공하는 Redis을 사용하는 것이 안전성 측면에서 유리해 보입니다. 비록 응답속도의 안정성 측면에서 Memcached에 비해 Redis가 불안정해 보이지만 Memcached에 비해 비교적 불안정하다는 것이지 단점으로 꼽힐만한 부분은 아니라고 생각합니다. 그리고 무엇보다 Spring에서 자체적으로 Redis API를 지원한다는 점이 편리하게 느껴집니다. 따라서 제가 사용하려는 'HELPARTY'에는 Redis 캐시 메모리를 사용하는 것으로 정했습니다.
'Project 'HELPARTY'' 카테고리의 다른 글
| 프로젝트에 적용할 Log 라이브러리 정하기 (0) | 2021.06.07 |
|---|---|
| 프로젝트에서 부가 로직 분리하기 [AOP_AspectJ, HandleMethodArgumentResolver] (0) | 2021.05.07 |
| 로그인을 검사해주는 부가 로직을 어떤 기술을 이용해서 분리할까? Filter & Interceptor & AOP (0) | 2021.04.06 |
| Sticky Session, Session Clustering, Session Storage 분리 (0) | 2021.03.12 |
| 스케일 아웃 (Scale Out) vs 스케일 업 (Scale Up) (0) | 2021.03.10 |
- Total
- Today
- Yesterday
- scale Out
- devops
- AOP
- interceptor
- redis
- 성능 테스트
- AWS
- logback
- 쿼리 튜닝
- memcached
- log4j2
- MySQL
- 선언적 트랜잭션
- scale in
- Filter
- 성능 향상
- 유틸클래스
- 로그
- Declarative Transaction
- UTIL
- nGrinder
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |